限流算法介绍
限流算法
大多数情况下,我们不需要自己实现一个限流系统,但限流在实际应用中是一个非常微妙、有很多细节的系统保护手段,尤其是在高流量时,了解你所使用的限流系统的限流算法,将能很好地帮助你充分利用该限流系统达到自己的商业需求和目的,并规避一些使用限流系统可能带来的大大小小的问题。
令牌桶算法
令牌桶(token bucket)算法,指的是设计一个容器(即“桶”),由某个组件持续运行往该容器中添加令牌(token),令牌可以是简单的数字、字符或组合,也可以仅仅是一个计数,然后每个请求进入系统时,需要从桶中领取一个令牌,所有请求都必须有令牌才能进入后端系统。当令牌桶空时,拒绝请求;当令牌桶满时,不再往其中添加新的令牌。 令牌桶算法的架构如图1所示:
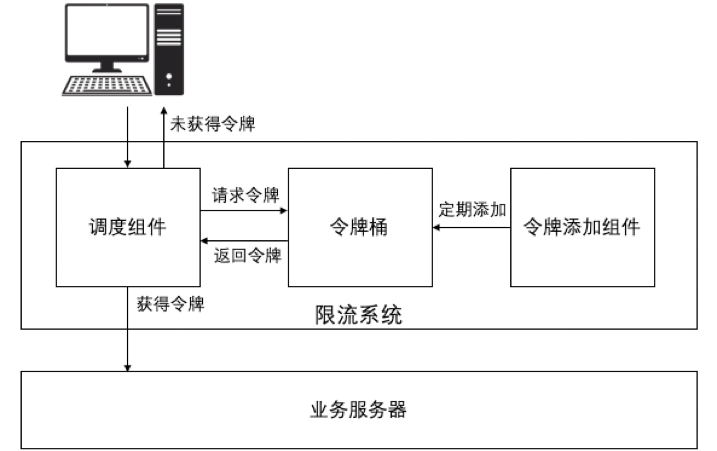
令牌桶算法的实现逻辑如下:
首先会有一个定义的时间窗口的访问次数阈值,例如每天1000人,每秒5个请求之类,限流系统一般最小粒度是秒,再小就会因为实现和性能的原因而变得不准确或不稳定,假设是T秒内允许N个请求,那么令牌桶算法则会使令牌添加组件每T秒往令牌桶中添加N个令牌。
其次,令牌桶需要有一个最大值M,当令牌添加组件检测到令牌桶中已经有M个令牌时,剩余的令牌会被丢弃。反映到限流系统中,可以认为是当前系统允许的瞬时最大流量,但不是持续最大流量。例如令牌桶中的令牌最大数量是100个,每秒钟会往其中添加10个新令牌,当令牌满的时候,突然出现100 TPS的流量,这时候是可以承受的,但是假如连续两秒的100 TPS流量就不行,因为令牌添加速度是一秒10个,添加速度跟不上使用速度。
因此,凡是使用令牌桶算法的限流系统,我们都会注意到它在配置时要求两个参数:
- 平均阈值(rate或average)
- 高峰阈值(burst或peak)
通过笔者的介绍,读者应该意识到,令牌桶算法的高峰阈值是有特指的,并不是指当前限流系统允许的最高流量。因为这一描述可能会使人认为只要低于该阈值的流量都可以,但事实上不是这样,因为只要高于添加速度的流量持续一段时间都会出现问题。
反过来说,令牌桶算法的限流系统不容易计算出它支持的最高流量,因为它能实时支持的最高流量取决于那整个时间段内的流量变化情况即令牌存量,而不是仅仅取决于一个瞬时的令牌量。
最后,当有组件请求令牌的时候,令牌桶会随机挑选一个令牌分发出去,然后将该令牌从桶中移除。注意,此时令牌桶不再做别的操作,令牌桶永远不会主动要求令牌添加组件补充新的令牌。
令牌桶算法有一个同一思想、方向相反的变种,被称为漏桶(leaky bucket)算法,它是令牌桶的一种改进,在商业应用中非常广泛。
漏桶算法的基本思想,是将请求看作水流,用一个底下有洞的桶盛装,底下的洞漏出水的速率是恒定的,所有请求进入系统的时候都会先进入这个桶,并慢慢由桶流出交给后台服务。桶有一个固定大小,当水流量超过这个大小的时候,多余的请求都会被丢弃。
漏桶算法的架构如图所示:
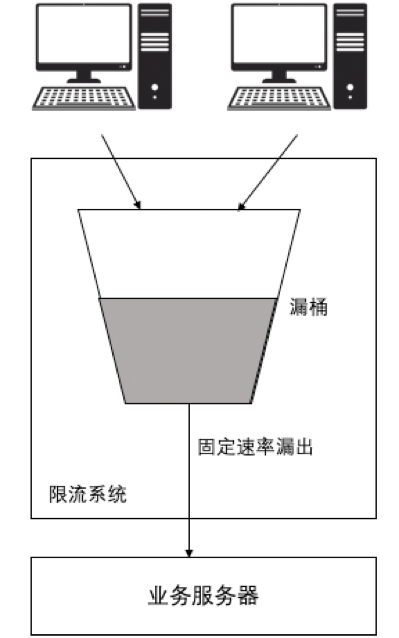
漏桶算法的实现逻辑如下:
- 首先会有一个容器存放请求,该容器有一个固定大小M,所有请求都会被先存放到该容器中。
- 该容器会有一个转发逻辑,该转发以每T秒N个请求的速率循环发生。
- 当容器中请求数已经达到M个时,拒绝所有新的请求。
因此同样地,漏桶算法的配置也需要两个值:平均值(rate)和峰值(burst)。只是平均值这时候是用来表示漏出的请求数量,峰值则是表示桶中可以存放的请求数量。
注意:漏桶算法和缓冲的限流思想不是一回事!
同样是将请求放在一个容器中,漏桶算法和缓冲不是一个用途,切不可搞混,它们的区别如下:
- 漏桶算法中,存在桶中的请求会以恒定的速率被漏给后端业务服务器,而缓冲思想中,放在缓冲区域的请求只有等到后端服务器空闲下来了,才会被发出去。
- 漏桶算法中,存在桶中的请求是原本就应该被系统处理的,是系统对外界宣称的预期,不应该被丢失,而缓冲思想中放在缓冲区域的请求仅仅是对意外状况的尽量优化,并没有任何强制要求这些请求可以被处理。
漏桶算法和令牌桶算法在思想上非常接近,而实现方向恰好相反,它们有如下的相同和不同之处:
- 令牌桶算法以固定速率补充可以转发的请求数量(令牌),而漏桶算法以固定速率转发请求;
- 令牌桶算法限制数量的是预算数,漏桶算法限制数量的是实际请求数;
- 令牌桶算法在有爆发式增长的流量时可以一定程度上接受,漏桶算法也是,但当流量爆发时,令牌桶算法会使业务服务器直接承担这种流量,而漏桶算法的业务服务器感受到的是一样的速率变化。
因此,通过以上比较,我们会发现漏桶算法略优于令牌桶算法,因为漏桶算法对流量控制更平滑,而令牌桶算法在设置的数值范围内,会将流量波动忠实地转嫁到业务服务器头上。
漏桶算法在Nginx和分布式的限流系统例如Redis的限流功能中都有广泛应用,是目前业界最流行的算法之一。
时间窗口算法
时间窗口算法是比较简单、基础的限流算法,由于它比较粗略,不适合大型、流量波动大或者有更精细的流量控制需求的网站。
时间窗口算法根据确定时间窗口的方式,可以分为两种:
- 固定时间窗口算法
- 滑动时间窗口算法
固定时间窗口算法最简单,相信如果让初次接触限流理念的读者去快速设计实现一个限流系统的话,也可以很快想到这种算法。这种算法即固定一个时间段内限定一个请求阈值,没有达到则让请求通过,达到数量阈值了就拒绝请求。步骤如下:
- 先确定一个起始时间点,一般就是系统启动的时间。
- 从起始时间点开始,根据我们的需求,设置一个最大值M,开始接受请求并从0开始为请求计数。
- 在时间段T内,请求计数超过M时,拒绝所有剩下的请求。
- 超过时间段T后,重置计数。
固定时间窗口算法的思路固然简单,但是它的逻辑是有问题的,它不适合流量波动大和有精细控制流量需求的服务。让我们看以下例子:
假设我们的时间段T是1秒,请求最大值是10,在第一秒内,请求数量分布是第500毫秒时有1个请求,第800毫秒时有9个请求,如图3所示:
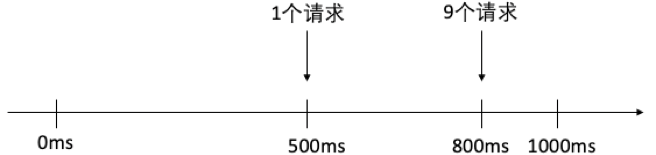
这是对于第一秒而言,这个请求分布是合理的。
此时第二秒的第200毫秒(即两秒中的第1200毫秒)内,又来了10个请求,如图4所示:

单独看第二秒依然是合理的,但是两个时间段连在一起的时候,就出现了问题,如图5所示:

从500毫秒到1200毫秒,短短700毫秒的时间内后端服务器就接收了20个请求,这显然违背了一开始我们希望1秒最多10个的初衷。这种远远大于预期流量的流量加到后端服务器头上,是会造成不可预料的后果的。因此,人们改进了固定窗口的算法,将其改为检查任何一个时间段都不超过请求数量阈值的时间窗口算法:滑动时间窗口算法。
滑动时间窗口算法要求当请求进入系统时,回溯过去的时间段T,找到其中的请求数量,然后决定是否接受当前请求,因此,滑动时间窗口算法需要记录时间段T内请求到达的时间点,逻辑如图6所示:
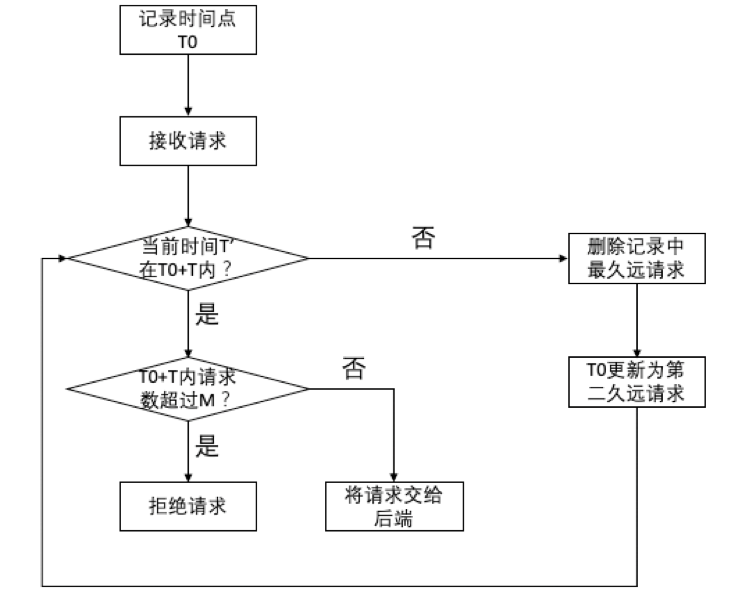
解释如下:
1、确定一个起始时间点,一般就是系统启动的时间,并记录该点为时间窗口的开始点。然后创建一个空的列表作为时间窗口内请求进入的时间戳记录。
2、当请求到来时,使用当前时间戳比较它是否在时间窗口起始点加上T时间段(从开始点到开始点+T就是时间窗口)内。
- 如果在,则查看当前时间窗口内记录的所有请求的数量:
- 如果超过,则拒绝请求。
- 如果没有,则将该请求加入到时间戳记录中,并将请求交给后端业务服务器。
- 如果不在,则查看时间戳记录,将时间戳最久远的记录删除,然后将时间窗口的开始点更新为第二久远的记录时间,然后回到步骤2,再次检查时间戳是否在时间窗口内。
滑动时间窗口尽管有所改进,但依然不能很好应对某个时间段内突发大量请求,而令牌桶和漏桶算法就由于允许指定平均请求率和最大瞬时请求率,它比时间窗口算法控制更精确。
时间窗口算法可以通过多时间窗口来改进。例如,可以设置一个1秒10 TPS的时间窗口限流和一个500毫秒5 TPS的时间窗口限流,二者同时运行,如此就可以保证更精确的限流控制。
队列法
队列法与漏桶算法很类似,都是将请求放入到一个区域,然后业务服务器从中提取请求,但是队列法采用的是完全独立的外部系统,而不是依附于限流系统。队列法的架构如图7所示:
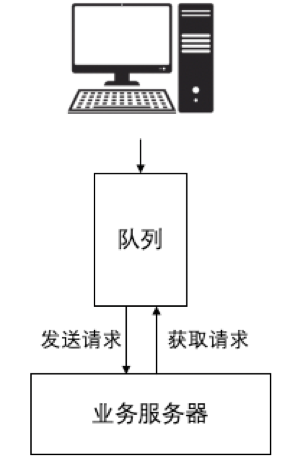
与漏桶算法相比,队列法的优势如下:
- 由业务逻辑层决定请求收取的速度。限流系统即队列不需要再关注流量的设置(例如T是多少,N是多少,M又是多少等等),只需要专注保留发送的请求,而业务服务器由于完全掌控消息的拉取,可以根据自身条件决定请求获取的速度,更加自由。
- 完全将业务逻辑层保护起来,并且可以增加服务去消费这些请求。这一手段将业务服务器完全隐藏在了客户端后面,由队列去承担所有流量,也可以更好地保护自身不受到恶意流量的攻击。
- 队列可以使用更健壮、更成熟的服务,这些服务比限流系统复杂,但能够承受大得多的流量。例如,业务服务器使用的是像阿里云或者AWS这样的消息队列的话,业务服务器就不用担心扩容的问题了,只要请求对实时性的要求不高。业务服务器由于使用了云服务,队列一端的扩容不用担心,而由于消息是自由决定拉取频率和处理速度,自身的扩容压力也就不那么大了。
但队列法最大的缺陷,就是服务器不能直接与客户端沟通,因此只适用于客户端令业务服务器执行任务且不要求响应的用例,所有客户端需要有实质响应的服务都不能使用。例如,业务服务器提供的服务是消息发送服务,那么这种模式就可以的,但如果客户端是请求某些用户信息,那这种方式就完全不可行了。
本文摘录自《深入浅出大型网站架构设计》