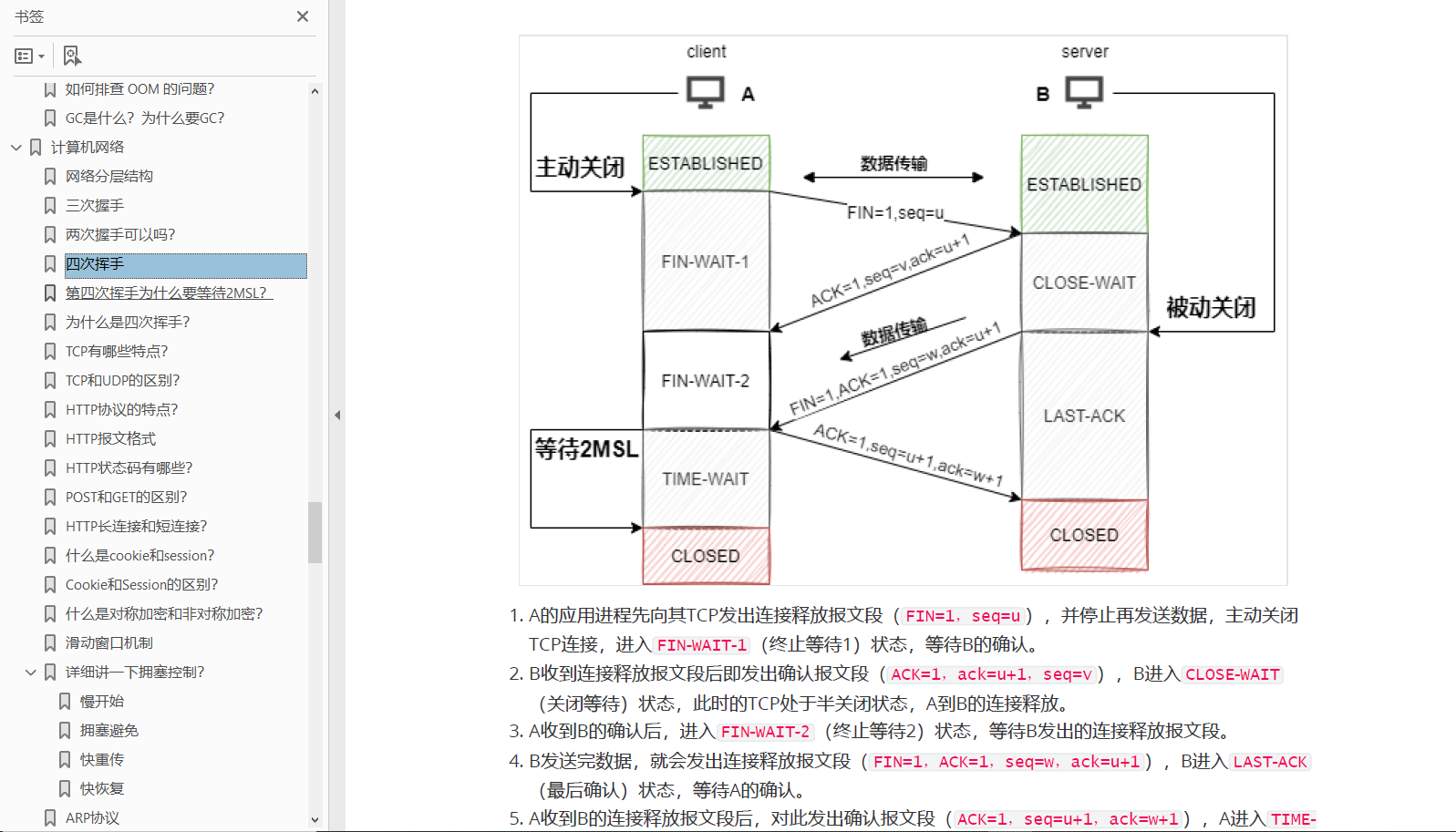
Spring源码分析
正文
此篇文章需要有SpringAOP基础,知道AOP底层原理可以更好的理解Spring的事务处理。最全面的Java面试网站
自定义标签
对于Spring中事务功能的代码分析,我们首先从配置文件开始人手,在配置文件中有这样一个配置:<tx:annotation-driven/>。可以说此处配置是事务的开关,如果没有此处配置,那么Spring中将不存在事务的功能。那么我们就从这个配置开始分析。
根据之前的分析,我们因此可以判断,在自定义标签中的解析过程中一定是做了一些辅助操作,于是我们先从自定义标签入手进行分析。使用Idea搜索全局代码,关键字annotation-driven,最终锁定类TxNamespaceHandler,在TxNamespaceHandler中的 init 方法中:
@Override
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
在遇到诸如tx:annotation-driven为开头的配置后,Spring都会使用AnnotationDrivenBeanDefinitionParser类的parse方法进行解析。
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
if ("aspectj".equals(mode)) {
// mode="aspectj"
registerTransactionAspect(element, parserContext);
if (ClassUtils.isPresent("javax.transaction.Transactional", getClass().getClassLoader())) {
registerJtaTransactionAspect(element, parserContext);
}
}
else {
// mode="proxy"
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
在解析中存在对于mode属性的判断,根据代码,如果我们需要使用AspectJ的方式进行事务切入(Spring中的事务是以AOP为基础的),那么可以使用这样的配置:
<tx:annotation-driven transaction-manager="transactionManager" mode="aspectj"/>
注册 InfrastructureAdvisorAutoProxyCreator
我们以默认配置为例进行分析,进人AopAutoProxyConfigurer类的configureAutoProxyCreator:
分享一份大彬精心整理的大厂面试手册,包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
需要的小伙伴可以自行下载:

public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {
//向IOC注册InfrastructureAdvisorAutoProxyCreator这个类型的Bean
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
String txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// Create the TransactionAttributeSource definition.
// 创建AnnotationTransactionAttributeSource类型的Bean
RootBeanDefinition sourceDef = new RootBeanDefinition("org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);
// Create the TransactionInterceptor definition.
// 创建TransactionInterceptor类型的Bean
RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);
// Create the TransactionAttributeSourceAdvisor definition.
// 创建BeanFactoryTransactionAttributeSourceAdvisor类型的Bean
RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
// 将上面AnnotationTransactionAttributeSource类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 将上面TransactionInterceptor类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
// 将上面三个Bean注册进IOC中
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
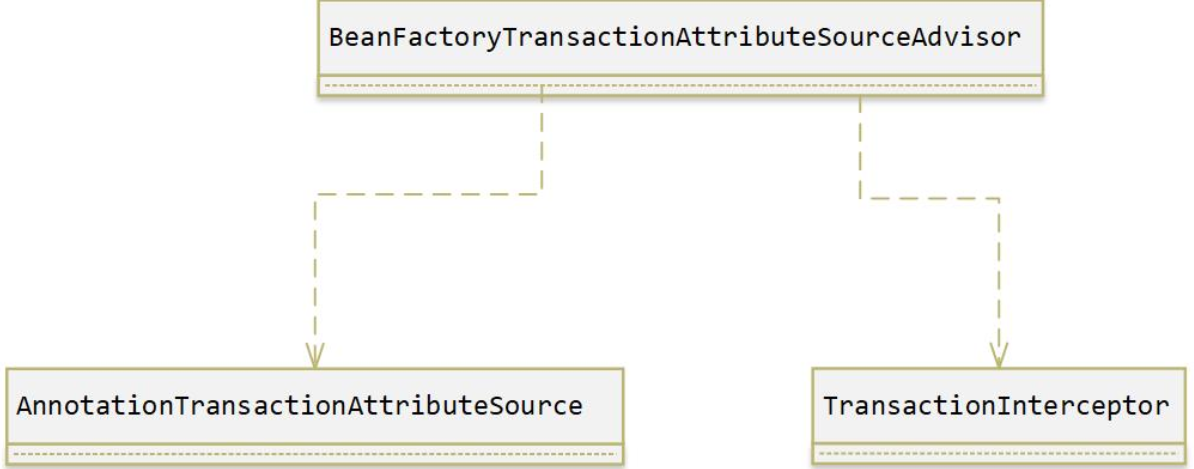
这里分别是注册了三个Bean,和一个InfrastructureAdvisorAutoProxyCreator,其中三个Bean支撑了整个事务的功能。
我们首先需要回顾一下AOP的原理,AOP中有一个 Advisor 存放在代理类中,而Advisor中有advise与pointcut信息,每次执行被代理类的方法时都会执行代理类的invoke(如果是JDK代理)方法,而invoke方法会根据advisor中的pointcut动态匹配这个方法需要执行的advise链,遍历执行advise链,从而达到AOP切面编程的目的。
BeanFactoryTransactionAttributeSourceAdvisor:首先看这个类的继承结构,可以看到这个类其实是一个Advisor,其实由名字也能看出来,类中有几个关键地方注意一下,在之前的注册过程中,将两个属性注入进这个Bean中:
// 将上面AnnotationTransactionAttributeSource类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 将上面TransactionInterceptor类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
那么它们被注入成什么了呢?进入BeanFactoryTransactionAttributeSourceAdvisor一看便知。
@Nullable
private TransactionAttributeSource transactionAttributeSource;
在其父类中有属性:
@Nullable
private String adviceBeanName;
也就是说,这里先将上面的TransactionInterceptor的BeanName传入到Advisor中,然后将AnnotationTransactionAttributeSource这个Bean注入到Advisor中,那么这个Source Bean有什么用呢?可以继续看看BeanFactoryTransactionAttributeSourceAdvisor的源码。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
@Nullable
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
看到这里应该明白了,这里的Source是提供了pointcut信息,作为存放事务属性的一个类注入进Advisor中,到这里应该知道注册这三个Bean的作用了吧?首先注册pointcut、advice、advisor,然后将pointcut和advice注入进advisor中,在之后动态代理的时候会使用这个Advisor去寻找每个Bean是否需要动态代理(取决于是否有开启事务),因为Advisor有pointcut信息。
- InfrastructureAdvisorAutoProxyCreator:在方法开头,首先就调用了AopNamespeceUtils去注册了这个Bean,那么这个Bean是干什么用的呢?还是先看看这个类的结构。这个类继承了AbstractAutoProxyCreator,看到这个名字,熟悉AOP的话应该已经知道它是怎么做的了吧?其次这个类还实现了BeanPostProcessor接口,凡事实现了这个BeanPost接口的类,我们首先关注的就是它的postProcessAfterInitialization方法,这里在其父类也就是刚刚提到的AbstractAutoProxyCreator这里去实现。(这里需要知道Spring容器初始化Bean的过程,关于BeanPostProcessor的使用我会另开一篇讲解。如果不知道只需了解如果一个Bean实现了BeanPostProcessor接口,当所有Bean实例化且依赖注入之后初始化方法之后会执行这个实现Bean的postProcessAfterInitialization方法)
进入这个函数:
public static void registerAutoProxyCreatorIfNecessary(
ParserContext parserContext, Element sourceElement) {
BeanDefinition beanDefinition = AopConfigUtils.registerAutoProxyCreatorIfNecessary(
parserContext.getRegistry(), parserContext.extractSource(sourceElement));
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
registerComponentIfNecessary(beanDefinition, parserContext);
}
@Nullable
public static BeanDefinition registerAutoProxyCreatorIfNecessary(BeanDefinitionRegistry registry,
@Nullable Object source) {
return registerOrEscalateApcAsRequired(InfrastructureAdvisorAutoProxyCreator.class, registry, source);
}
对于解析来的代码流程AOP中已经有所分析,上面的两个函数主要目的是注册了InfrastructureAdvisorAutoProxyCreator类型的bean,那么注册这个类的目的是什么呢?查看这个类的层次,如下图所示:
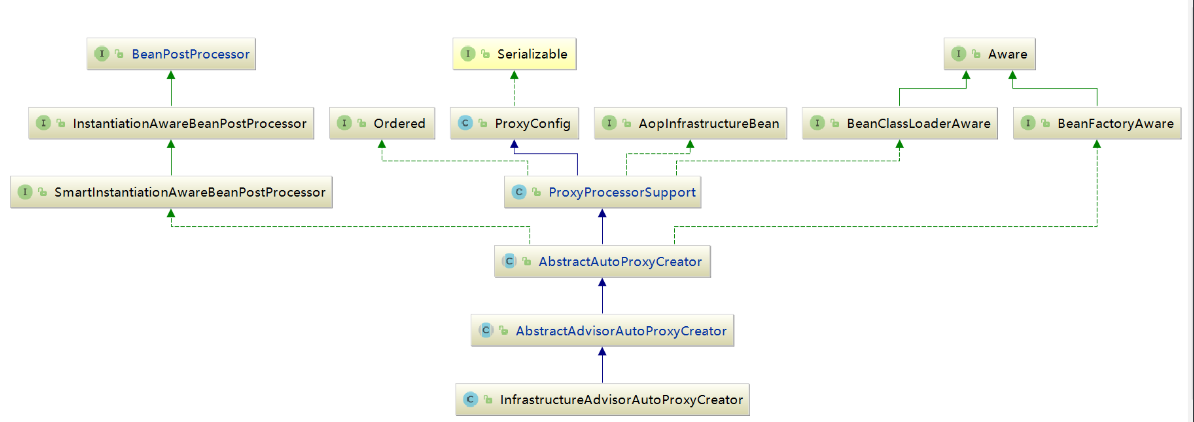
从上面的层次结构中可以看到,InfrastructureAdvisorAutoProxyCreator间接实现了SmartInstantiationAwareBeanPostProcessor,而SmartInstantiationAwareBeanPostProcessor又继承自InstantiationAwareBeanPostProcessor,也就是说在Spring中,所有bean实例化时Spring都会保证调用其postProcessAfterInstantiation方法,其实现是在父类AbstractAutoProxyCreator类中实现。
以之前的示例为例,当实例化AccountServiceImpl的bean时便会调用此方法,方法如下:
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
// 根据给定的bean的class和name构建出key,格式:beanClassName_beanName
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
// 如果它适合被代理,则需要封装指定bean
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
这里实现的主要目的是对指定bean进行封装,当然首先要确定是否需要封装,检测与封装的工作都委托给了wrapIfNecessary函数进行。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 如果处理过这个bean的话直接返回
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
// 之后如果Bean匹配不成功,会将Bean的cacheKey放入advisedBeans中
// value为false,所以这里可以用cacheKey判断此bean是否之前已经代理不成功了
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
// 这里会将Advise、Pointcut、Advisor类型的类过滤,直接不进行代理,return
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
// 这里即为不成功的情况,将false放入Map中
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
// 这里是主要验证的地方,传入Bean的class与beanName去判断此Bean有哪些Advisor
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 如果有相应的advisor被找到,则用advisor与此bean做一个动态代理,将这两个的信息
// 放入代理类中进行代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理的地方
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
// 返回代理对象
return proxy;
}
// 如果此Bean没有一个Advisor匹配,将返回null也就是DO_NOT_PROXY
// 也就是会走到这一步,将其cacheKey,false存入Map中
this.advisedBeans.put(cacheKey, Boolean.FALSE);
// 不代理直接返回原bean
return bean;
}
wrapIfNecessary函数功能实现起来很复杂,但是逻辑上理解起来还是相对简单的,在wrapIfNecessary函数中主要的工作如下:
(1)找出指定bean对应的增强器。
(2)根据找出的增强器创建代理。
听起来似乎简单的逻辑,Spring中又做了哪些复杂的工作呢?对于创建代理的部分,通过之前的分析相信大家已经很熟悉了,但是对于增强器的获取,Spring又是怎么做的呢?
获取对应class/method的增强器
获取指定bean对应的增强器,其中包含两个关键字:增强器与对应。也就是说在 getAdvicesAndAdvisorsForBean函数中,不但要找出增强器,而且还需要判断增强器是否满足要求。
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
寻找候选增强器
protected List<Advisor> findCandidateAdvisors() {
Assert.state(this.advisorRetrievalHelper != null, "No BeanFactoryAdvisorRetrievalHelper available");
return this.advisorRetrievalHelper.findAdvisorBeans();
}
public List<Advisor> findAdvisorBeans() {
// Determine list of advisor bean names, if not cached already.
String[] advisorNames = this.cachedAdvisorBeanNames;
if (advisorNames == null) {
// 获取BeanFactory中所有对应Advisor.class的类名
// 这里和AspectJ的方式有点不同,AspectJ是获取所有的Object.class,然后通过反射过滤有注解AspectJ的类
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Advisor.class, true, false);
this.cachedAdvisorBeanNames = advisorNames;
}
if (advisorNames.length == 0) {
return new ArrayList<>();
}
List<Advisor> advisors = new ArrayList<>();
for (String name : advisorNames) {
if (isEligibleBean(name)) {
if (this.beanFactory.isCurrentlyInCreation(name)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping currently created advisor '" + name + "'");
}
}
else {
try {
//直接获取advisorNames的实例,封装进advisors数组
advisors.add(this.beanFactory.getBean(name, Advisor.class));
}
catch (BeanCreationException ex) {
Throwable rootCause = ex.getMostSpecificCause();
if (rootCause instanceof BeanCurrentlyInCreationException) {
BeanCreationException bce = (BeanCreationException) rootCause;
String bceBeanName = bce.getBeanName();
if (bceBeanName != null && this.beanFactory.isCurrentlyInCreation(bceBeanName)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping advisor '" + name +
"' with dependency on currently created bean: " + ex.getMessage());
}
continue;
}
}
throw ex;
}
}
}
}
return advisors;
}
首先是通过BeanFactoryUtils类提供的工具方法获取所有对应Advisor.class的类,获取办法无非是使用ListableBeanFactory中提供的方法:
String[] getBeanNamesForType(@Nullable Class<?> type, boolean includeNonSingletons, boolean allowEagerInit);
在我们讲解自定义标签时曾经注册了一个类型为 BeanFactoryTransactionAttributeSourceAdvisor 的 bean,而在此 bean 中我们又注入了另外两个Bean,那么此时这个 Bean 就会被开始使用了。因为 BeanFactoryTransactionAttributeSourceAdvisor同样也实现了 Advisor接口,那么在获取所有增强器时自然也会将此bean提取出来, 并随着其他增强器一起在后续的步骤中被织入代理。
候选增强器中寻找到匹配项
当找出对应的增强器后,接下来的任务就是看这些增强器是否与对应的class匹配了,当然不只是class,class内部的方法如果匹配也可以通过验证。
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
List<Advisor> eligibleAdvisors = new ArrayList<>();
// 首先处理引介增强
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
// 引介增强已经处理
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
// 对于普通bean的处理
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
return eligibleAdvisors;
}
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor) advisor).getClassFilter().matches(targetClass);
}
else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor) advisor;
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
BeanFactoryTransactionAttributeSourceAdvisor 间接实现了PointcutAdvisor。 因此,在canApply函数中的第二个if判断时就会通过判断,会将BeanFactoryTransactionAttributeSourceAdvisor中的getPointcut()方法返回值作为参数继续调用canApply方法,而 getPoint()方法返回的是TransactionAttributeSourcePointcut类型的实例。对于 transactionAttributeSource这个属性大家还有印象吗?这是在解析自定义标签时注入进去的。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
@Nullable
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
那么,使用TransactionAttributeSourcePointcut类型的实例作为函数参数继续跟踪canApply。
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
Assert.notNull(pc, "Pointcut must not be null");
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
// 此时的pc表示TransactionAttributeSourcePointcut
// pc.getMethodMatcher()返回的正是自身(this)
MethodMatcher methodMatcher = pc.getMethodMatcher();
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher) {
introductionAwareMethodMatcher = (IntroductionAwareMethodMatcher) methodMatcher;
}
Set<Class<?>> classes = new LinkedHashSet<>();
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
//获取对应类的所有接口
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
//对类进行遍历
for (Class<?> clazz : classes) {
//反射获取类中所有的方法
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
//对类和方法进行增强器匹配
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
return false;
}
通过上面函数大致可以理清大体脉络,首先获取对应类的所有接口并连同类本身一起遍历,遍历过程中又对类中的方法再次遍历,一旦匹配成功便认为这个类适用于当前增强器。
到这里我们不禁会有疑问,对于事物的配置不仅仅局限于在函数上配置,我们都知道,在类或接口上的配置可以延续到类中的每个函数,那么,如果针对每个函数迸行检测,在类本身上配罝的事务属性岂不是检测不到了吗?带着这个疑问,我们继续探求matcher方法。
做匹配的时候 methodMatcher.matches(method, targetClass)会使用 TransactionAttributeSourcePointcut 类的 matches 方法。
@Override
public boolean matches(Method method, Class<?> targetClass) {
if (TransactionalProxy.class.isAssignableFrom(targetClass)) {
return false;
}
// 自定义标签解析时注入
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
此时的 tas 表示 AnnotationTransactionAttributeSource 类型,这里会判断**tas.getTransactionAttribute(method, targetClass) != null,**而 AnnotationTransactionAttributeSource 类型的 getTransactionAttribute 方法如下:
@Override
@Nullable
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
Object cacheKey = getCacheKey(method, targetClass);
Object cached = this.attributeCache.get(cacheKey);
//先从缓存中获取TransactionAttribute
if (cached != null) {
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return (TransactionAttribute) cached;
}
}
else {
// 如果缓存中没有,工作又委托给了computeTransactionAttribute函数
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
// 设置为空
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
//加入缓存中
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
尝试从缓存加载,如果对应信息没有被缓存的话,工作又委托给了computeTransactionAttribute函数,在computeTransactionAttribute函数中我们终于看到了事务标签的提取过程。
提取事务标签
@Nullable
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
// method代表接口中的方法,specificMethod代表实现类中的方法
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// First try is the method in the target class.
// 查看方法中是否存在事务声明
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
// 查看方法所在类中是否存在事务声明
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
// 如果存在接口,则到接口中去寻找
if (specificMethod != method) {
// Fallback is to look at the original method.
// 查找接口方法
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
// 到接口中的类中去寻找
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
对于事务属性的获取规则相信大家都已经很清楚,如果方法中存在事务属性,则使用方法上的属性,否则使用方法所在的类上的属性,如果方法所在类的属性上还是没有搜寻到对应的事务属性,那么在搜寻接口中的方法,再没有的话,最后尝试搜寻接口的类上面的声明。对于函数computeTransactionAttribute中的逻辑与我们所认识的规则并无差別,但是上面函数中并没有真正的去做搜寻事务属性的逻辑,而是搭建了个执行框架,将搜寻事务属性的任务委托给了 findTransactionAttribute 方法去执行。
@Override
@Nullable
protected TransactionAttribute findTransactionAttribute(Class<?> clazz) {
return determineTransactionAttribute(clazz);
}
@Nullable
protected TransactionAttribute determineTransactionAttribute(AnnotatedElement ae) {
for (TransactionAnnotationParser annotationParser : this.annotationParsers) {
TransactionAttribute attr = annotationParser.parseTransactionAnnotation(ae);
if (attr != null) {
return attr;
}
}
return null;
}
this.annotationParsers 是在当前类 AnnotationTransactionAttributeSource 初始化的时候初始化的,其中的值被加入了 SpringTransactionAnnotationParser,也就是当进行属性获取的时候其实是使用 SpringTransactionAnnotationParser 类的 parseTransactionAnnotation 方法进行解析的。
@Override
@Nullable
public TransactionAttribute parseTransactionAnnotation(AnnotatedElement ae) {
AnnotationAttributes attributes = AnnotatedElementUtils.findMergedAnnotationAttributes(
ae, Transactional.class, false, false);
if (attributes != null) {
return parseTransactionAnnotation(attributes);
}
else {
return null;
}
}
至此,我们终于看到了想看到的获取注解标记的代码。首先会判断当前的类是否含有 Transactional注解,这是事务属性的基础,当然如果有的话会继续调用parseTransactionAnnotation 方法解析详细的属性。
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
// 解析propagation
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
// 解析isolation
rbta.setIsolationLevel(isolation.value());
// 解析timeout
rbta.setTimeout(attributes.getNumber("timeout").intValue());
// 解析readOnly
rbta.setReadOnly(attributes.getBoolean("readOnly"));
// 解析value
rbta.setQualifier(attributes.getString("value"));
ArrayList<RollbackRuleAttribute> rollBackRules = new ArrayList<>();
// 解析rollbackFor
Class<?>[] rbf = attributes.getClassArray("rollbackFor");
for (Class<?> rbRule : rbf) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析rollbackForClassName
String[] rbfc = attributes.getStringArray("rollbackForClassName");
for (String rbRule : rbfc) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackFor
Class<?>[] nrbf = attributes.getClassArray("noRollbackFor");
for (Class<?> rbRule : nrbf) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackForClassName
String[] nrbfc = attributes.getStringArray("noRollbackForClassName");
for (String rbRule : nrbfc) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
rbta.getRollbackRules().addAll(rollBackRules);
return rbta;
}
至此,我们终于完成了事务标签的解析。回顾一下,我们现在的任务是找出某个增强器是否适合于对应的类,而是否匹配的关键则在于是否从指定的类或类中的方法中找到对应的事务属性,现在,我们以AccountServiceImpl为例,已经在它的接口AccountServiceImp中找到了事务属性,所以,它是与事务增强器匹配的,也就是它会被事务功能修饰。
至此,事务功能的初始化工作便结束了,当判断某个bean适用于事务增强时,也就是适用于增强器BeanFactoryTransactionAttributeSourceAdvisor。
BeanFactoryTransactionAttributeSourceAdvisor 作为 Advisor 的实现类,自然要遵从 Advisor 的处理方式,当代理被调用时会调用这个类的增强方法,也就是此bean的Advice,又因为在解析事务定义标签时我们把Transactionlnterceptor类的bean注人到了 BeanFactoryTransactionAttributeSourceAdvisor中,所以,在调用事务增强器增强的代理类时会首先执行Transactionlnterceptor进行增强,同时,也就是在Transactionlnterceptor类中的invoke方法中完成了整个事务的逻辑。
最后给大家分享一个Github仓库,上面有大彬整理的300多本经典的计算机书籍PDF,包括C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~


如果访问不了Github,可以访问码云地址。