分布式锁
分布式锁
为什么要使用分布式锁
在单机环境下,当存在多个线程可以同时改变某个变量(可变共享变量)时,就会出现线程安全问题。这个问题可以通过 JAVA 提供的 volatile、ReentrantLock、synchronized 以及 concurrent 并发包下一些线程安全的类等来避免。
而在多机部署环境,需要在多进程下保证线程的安全性,Java提供的这些API仅能保证在单个JVM进程内对多线程访问共享资源的线程安全,已经不满足需求了。这时候就需要使用分布式锁来保证线程安全。通过分布式锁,可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
分布式锁应该具备哪些条件
在分析分布式锁的三种实现方式之前,先了解一下分布式锁应该具备哪些条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会死锁。具备锁失效机制,防止死锁。即使有客户端在持有锁的期间崩溃而没有主动解锁,也要保证后续其他客户端能加锁。
- 加锁和解锁必须是同一个客户端。客户端a不能将客户端b的锁解开,即不能误解锁。
- 高性能、高可用的获取锁与释放锁。
- 具备可重入特性。
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
分布式锁的三种实现方式
- 基于数据库实现分布式锁;
- 基于缓存(Redis等)实现分布式锁;
- 基于Zookeeper实现分布式锁。
基于数据库的实现方式
悲观锁
创建一张锁表,然后通过操作该表中的数据来实现加锁和解锁。当要锁住某个方法或资源时,就向该表插入一条记录,表中设置方法名为唯一键,这样多个请求同时提交数据库时,只有一个操作可以成功,判定操作成功的线程获得该方法的锁,可以执行方法内容;想要释放锁的时候就删除这条记录,其他线程就可以继续往数据库中插入数据获取锁。
乐观锁
每次更新操作,都觉得不会存在并发冲突,只有更新失败后,才重试。
扣减余额就可以使用这种方案。
具体实现:增加个version字段,每次更新修改,都会自增加一,然后去更新余额时,把查出来的那个版本号,带上条件去更新,如果是上次那个版本号,就更新,如果不是,表示别人并发修改过了,就继续重试。
基于Redis的实现方式
简单实现
Redis 2.6.12 之前的版本中采用 setnx + expire 方式实现分布式锁,在 Redis 2.6.12 版本后 setnx 增加了过期时间参数:
SET lockKey value NX PX expire-time
所以在Redis 2.6.12 版本后,只需要使用setnx就可以实现分布式锁了。
加锁逻辑:
- setnx争抢key的锁,如果已有key存在,则不作操作,过段时间继续重试,保证只有一个客户端能持有锁。
- value设置为 requestId(可以使用机器ip拼接当前线程名称),表示这把锁是哪个请求加的,在解锁的时候需要判断当前请求是否持有锁,防止误解锁。比如客户端A加锁,在执行解锁之前,锁过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
- 再用expire给锁加一个过期时间,防止异常导致锁没有释放。
解锁逻辑:
首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁。使用lua脚本实现原子操作,保证线程安全。
下面我们通过Jedis(基于java语言的redis客户端)来演示分布式锁的实现。
Jedis实现分布式锁
引入Jedis jar包,在pom.xml文件增加代码:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
加锁
调用jedis的set()实现加锁,加锁代码如下:
/**
* @description:
* @author: 程序员大彬
* @time: 2021-08-01 17:13
*/
public class RedisTest {
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_EXPIRE_TIME = "PX";
@Autowired
private JedisPool jedisPool;
public boolean tryGetDistributedLock(String lockKey, String requestId, int expireTime) {
Jedis jedis = jedisPool.getResource();
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
各参数说明:
- lockKey:使用key来当锁,需要保证key是唯一的。可以使用系统号拼接自定义的key。
- requestId:表示这把锁是哪个请求加的,可以使用机器ip拼接当前线程名称。在解锁的时候需要判断当前请求是否持有锁,防止误解锁。比如客户端A加锁,在执行解锁之前,锁过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
- NX:意思是SET IF NOT EXIST,保证如果已有key存在,则不作操作,过段时间继续重试。NX参数保证只有一个客户端能持有锁。
- PX:给key加一个过期的设置,具体时间由expireTime决定。
- expireTime:设置key的过期时间,防止异常导致锁没有释放。
解锁
首先需要获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁。这里使用lua脚本实现原子操作,保证线程安全。
使用eval命令执行Lua脚本的时候,不会有其他脚本或 Redis 命令被执行,实现组合命令的原子操作。lua脚本如下:
//KEYS[1]是lockKey,ARGV[1]是requestId
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
Jedis的eval()方法源码如下:
public Object eval(String script, List<String> keys, List<String> args) {
return this.eval(script, keys.size(), getParams(keys, args));
}
lua脚本的意思是:调用get获取锁(KEYS[1])对应的value值,检查是否与requestId(ARGV[1])相等,如果相等则调用del删除锁。否则返回0。
完整的解锁代码如下:
/**
* @description:
* @author: 程序员大彬
* @time: 2021-08-01 17:13
*/
public class RedisTest {
private static final Long RELEASE_SUCCESS = 1L;
@Autowired
private JedisPool jedisPool;
public boolean releaseDistributedLock(String lockKey, String requestId) {
Jedis jedis = jedisPool.getResource();
////KEYS[1]是lockKey,ARGV[1]是requestId
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
RedLock
前面的方案是基于Redis单机版的分布式锁讨论,还不是很完美。因为Redis一般都是集群部署的。

如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以顺理成章获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者antirez提出一种高级的分布式锁算法:Redlock。它的核心思想是这样的:
部署多个Redis master,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
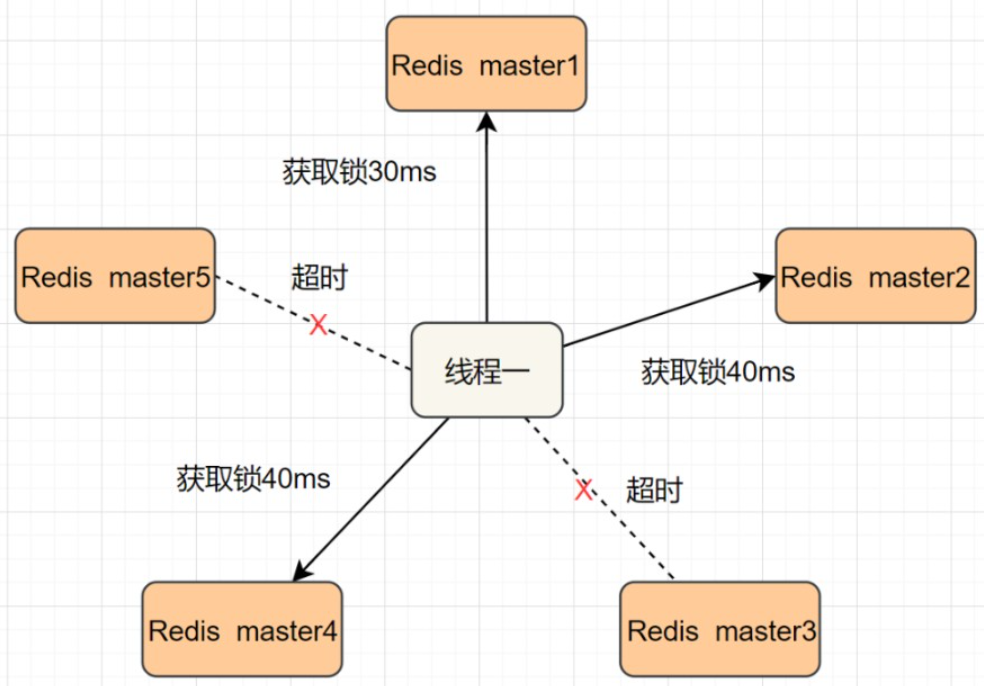
RedLock的实现步骤:
- 获取当前时间,以毫秒为单位。
- 按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
Redisson 实现了 redLock 版本的锁,有兴趣的小伙伴,可以去了解一下。
基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock; (2)线程A想获取锁就在mylock目录下创建临时顺序节点; (3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁; (4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点; (5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
三种实现方式对比
数据库分布式锁实现
优点:
- 简单,使用方便,不需要引入
Redis、zookeeper等中间件。
缺点:
- 不适合高并发的场景
- db操作性能较差;
Redis分布式锁实现
优点:
- 性能好,适合高并发场景
- 较轻量级
- 有较好的框架支持,如Redisson
缺点:
- 过期时间不好控制
- 需要考虑锁被别的线程误删场景
Zookeeper分布式锁实现
缺点:
- 性能不如redis实现的分布式锁
- 比较重的分布式锁。
优点:
- 有较好的性能和可靠性
- 有封装较好的框架,如Curator
对比汇总
- 从性能角度(从高到低)Redis > Zookeeper >= 数据库;
- 从理解的难易程度角度(从低到高)数据库 > Redis > Zookeeper;
- 从实现的复杂性角度(从低到高)Zookeeper > Redis > 数据库;
- 从可靠性角度(从高到低)Zookeeper > Redis > 数据库。