最近的生产慢查询问题分析与总结
1.问题描述
前几天凌晨出现大量慢查询告警,经DBA定位为某个子系统涉及的一条查询语句出现慢查询,引起数据库服务器的cpu使用率突增,触发大量告警,查看生产执行计划发现慢查询为索引跳变引起;具体出现问题的sql语句如下:
select * from ( select t.goods id as cardid,p.validate as validate, p.create timecreateTime
p.repay_coupon type as repaycoupontype,p.require anount as requireAmount, p.goods tag as goodsTag,
p.deduction anount as deductionAmount, p.repay coupon remark as repay(ouponkemark,
p.sale_point as salepoint from user_prizes p join trans_order t
on p.user_id = t.user_id and p.order_no = t.order_no
where p.user_id = #{user_id} and p.wmkt_type = '6' and t.status = 's' and p.equity_code_status = 'N'
and p.create_time >= #{beginDate}
order by p.create_time dese limit 1000) as cc group by cc.cardid:
该sql为查询三个月内满足条件的还款代金券列表,其中user_prizes表和trans_order表都是大表,数据量达到亿级别,user_prizes表有如下几个索引:
PRIMARY KEY ('merchant_order_no ,partition key ) USING BTREE,
KEY “thirdOrderNo" ("third_order_no","app_id"),
KEY "createTime" ("create_time"),
KEY "userId" ("user_id"),
KEY "time_activity" ("create_time', 'activity_name')
正常情况下该语句走的userId索引,当天零点后该sql语句出现索引跳变,走了createTime索引,导致出现慢查询。
2.问题处理方式
生产定位到问题后,因该sql的查询场景为前端触发,当天为账单日,请求量大,DBA通过kill脚本临时进行处理,同时准备增加强制索引优化的紧急版本,通过加上强制索引force index(userId)处理索引跳变,DBA也同步在备库删除createTime索引观察效果,准备进行主备切换尝试解决,但在备库执行索引删除后查看执行计划发现又走了time_activity索引,最后通过发布增加强制索引优化的紧急版本进行解决。
3.问题分析
MySQL优化器选择索引的目的是找到一个最优的执行方案,并用最小的代价去执行语句,扫描行数是影响执行代价的重要因素,扫描行数越少,意味着访问磁盘数据次数越少,消耗的cpu资源越少,除此之外,优化器还会结合是否使用临时表,以及是否排序等因素综合判断。
出现索引跳变的这个sql有order by create_time,且create_time为索引,user_prizes表是按月分区的,数据总量为1亿400多万,通过统计生产数据量分布情况发现,近几个月的分区数据量如下:
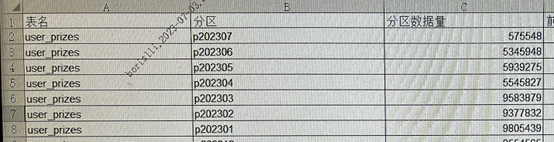
该sql7月1日零点后查询的是4月1日之后的数据,3月份分区的数据量为958万多,4月之后分区数量都保持在500多万。4月份之后分区数据减少了,可能是这个原因导致优化器认为走时间索引createTime的区分度更高,同时还可以避免排序,因而选择了时间索引。查看索引跳变后的执行计划如下:

走createTime索引虽然可以避免排序,但从执行计划的type=range可看出为索引范围的扫描,根据索引createTime扫描记录,通过索引叶子节点的主键值回表查找完整记录,然后判断记录中满足sql过滤条件的数据,再将结果进行返回,而该语句为查找满足条件的1000条数据,正常情况下一个user_id满足条件的数据量不会超过1000条,要找到所有满足条件的记录就是索引范围的扫描加回表查询,加上查询范围内的数据量大,因此走createTime索引就会非常慢。
4.总结
由于mysql在真正执行语句的时候,并不能准确的知道满足这个条件的记录有多少,只能通过统计信息来估算记录,而优化器并不是非常智能的,就有可能发生索引跳变的情况,这种情况很难在测试的时候复现出来,生产也可能是突然出现,所以我们只能在使用上尽量的去降低索引发生跳变的可能性,尽量避免出现该问题。我们可以在创建索引和使用sql的时候通过以下几个点进行检视。
(1) 索引的创建
创建索引的时候要注意尽量避免创建单列的时间字段(createTime、updateTime)索引,避免留坑,因为很多场景都可能用到时间字段进行排序,有排序的情况若排序字段又是单列索引字段,就可能引起索引跳变,如果需要使用时间字段作为索引时,尽量使用联合索引,且时间字段放在后面;高效的索引应遵循高区分度字段+避免排序的原则。
创建索引的时候也要尽量避免索引重复,且一张表的索引个数也要控制好,索引过多也会影响增删改的效率。
(2) sql的检视
检视历史和新增的sql是否有order by,且order by的第一个字段是否有单列索引,这种存在索引跳变的风险,需要具体分析后进行优化;
写sql语句的时候,尽可能简单化,像union、排序等尽量少在sql中实现,减少sql慢查询的风险。