Redis其他知识点
其他
客户端
Redis 客户端与服务端之间的通信协议是在TCP协议之上构建的。
Redis Monitor 命令用于实时打印出 Redis 服务器接收到的命令,调试用。
redis 127.0.0.1:6379> MONITOR
OK
1410855382.370791 [0 127.0.0.1:60581] "info"
1410855404.062722 [0 127.0.0.1:60581] "get" "a"
慢查询
Redis原生提供慢查询统计功能,执行slowlog get{n}命令可以获取最近的n条慢查询命令,默认对于执行超过10毫秒的命令都会记录到一个定长队列中,线上实例建议设置为1毫秒便于及时发现毫秒级以上的命令。慢查询队列长度默认128,可适当调大。
Redis客户端执行一条命令分为4个部分:发送命令;命令排队;命令执行;返回结果。慢查询只统计命令执行这一步的时间,所以没有慢查询并不代表客户端没有超时问题。
Redis提供了slowlog-log-slower-than(设置慢查询阈值,单位为微秒)和slowlog-max-len(慢查询队列大小)配置慢查询参数。
相关命令:
showlog get n //获取慢查询日志
slowlog len //慢查询日志队列当前长度
slowlog reset //重置,清理列表
慢查询解决方案:
- 修改为低时间复杂度的命令,如hgetall改为hmget等,禁用keys、sort等命令。
- 调整大对象:缩减大对象数据或把大对象拆分为多个小对象,防止一次命令操作过多的数据。
pipeline
redis客户端执行一条命令分4个过程: 发送命令-〉命令排队-〉命令执行-〉返回结果。使用Pipeline可以批量请求,批量返回结果,执行速度比逐条执行要快。
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成。
原生批命令(mset, mget)与Pipeline对比:
原生批命令是原子性,pipeline是非原子性。pipeline命令中途异常退出,之前执行成功的命令不会回滚。
原生批命令只有一个命令, 但pipeline支持多命令。
数据一致性
缓存和DB之间怎么保证数据一致性: 读操作:先读缓存,缓存没有的话读DB,然后取出数据放入缓存,最后响应数据 写操作:先删除缓存,再更新DB 为什么是删除缓存而不是更新缓存呢?
- 线程安全问题。同时有请求A和请求B进行更新操作,那么会出现(1)线程A更新了缓存(2)线程B更新了缓存(3)线程B更新了数据库(4)线程A更新了数据库,由于网络等原因,请求B先更新数据库,这就导致缓存和数据库不一致的问题。
- 如果业务需求写数据库场景比较多,而读数据场景比较少,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。
- 如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。
先删除缓存,再更新DB,同样也有问题。假如A先删除了缓存,但还没更新DB,这时B过来请求数据,发现缓存没有,去请求DB拿到旧数据,然后再写到缓存,等A更新完了DB之后就会出现缓存和DB数据不一致的情况了。
解决方法:采用延时双删策略。更新完数据库之后,延时一段时间,再次删除缓存,确保可以删除读请求造成的缓存脏数据。评估项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);//确保读请求结束,写请求可以删除读请求造成的缓存脏数据
redis.delKey(key);
}
可以将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,加大吞吐量。
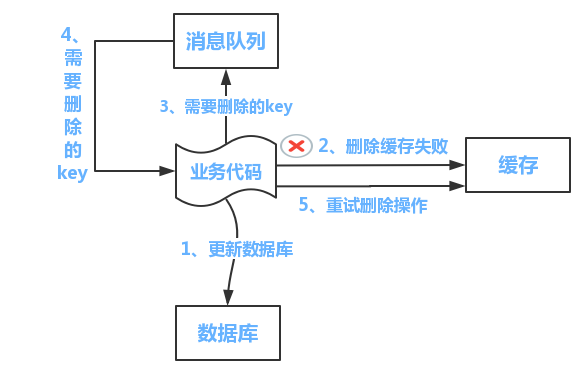
当删缓存失败时,也会就出现数据不一致的情况。
解决方法: