Redis数据结构
数据结构
动态字符串
SDS(simple dynamic string,SDS),简单动态字符串,其定义如下:
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
在64位系统下,属性len和属性free各占4个字节,紧接着存放字节数组。
下面展示一个SDS示例:
set name "Redis"
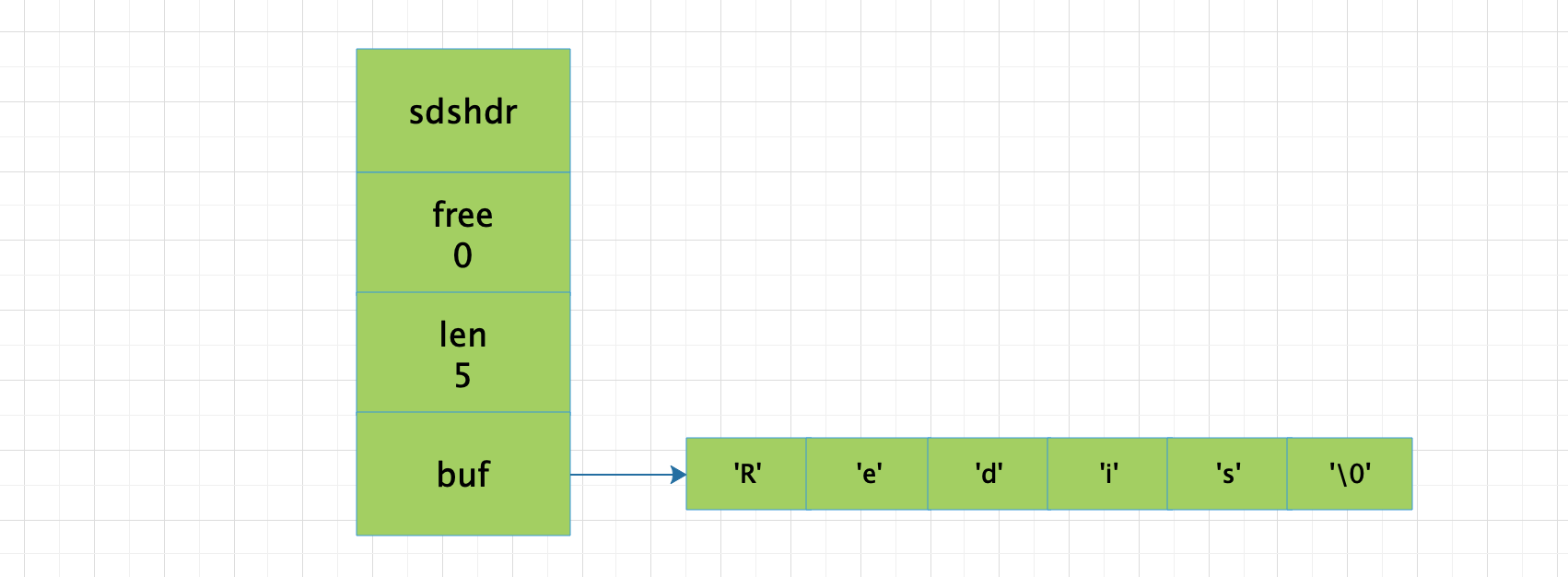
free属性的值为0,表示这个SDS没有分配任何未使用空间。
len属性的值为5,表示这个SDS保存了一个物字节长的字符串。
buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而最后一个字节则保存了空字符'\0'。
SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配额外的1字节空间,以及添加空字符到字符串末尾等操作,都是由SDS函数自动完成的,所以这个空字符对于SDS的使用者来说是完全透明的。遵循空字符串结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
下面是SDS与C字符串的区别。
| C 字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度为 O(N) 。 | 获取字符串长度的复杂度为 O(1) 。 |
| API 是不安全的,可能会造成缓冲区溢出。 | API 是安全的,不会造成缓冲区溢出。 |
修改字符串长度 N 次必然需要执行 N 次内存重分配。 | 修改字符串长度 N 次最多需要执行 N 次内存重分配。 |
| 只能保存文本数据。 | 可以保存文本或者二进制数据。 |
可以使用所有 <string.h> 库中的函数。 | 可以使用一部分 <string.h> 库中的函数。 |
字典
字典使用hashtable作为底层实现。键值对的值可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数。
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
整数集合
整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构, 它可以保存类型为 int16_t 、 int32_t 或者 int64_t 的整数值, 并且保证集合中不会出现重复元素。
压缩列表
ziplist是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。每个压缩列表节点都由 previous_entry_length 、 encoding 、 content 三个部分组成。
节点的 previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。 节点的 encoding 属性记录了节点的 content 属性所保存数据的类型以及长度。有两种编码方式,字节数组编码和整数编码。
压缩列表的从表尾向表头遍历操作就是使用这一原理实现的: 只要我们拥有了一个指向某个节点起始地址的指针, 那么通过这个指针以及这个节点的 previous_entry_length 属性, 程序就可以一直向前一个节点回溯, 最终到达压缩列表的表头节点。
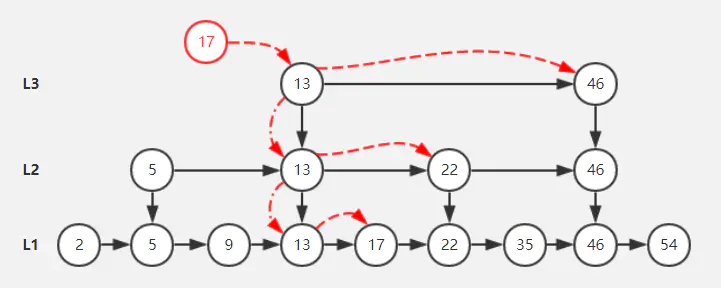
跳表
跳表可以看成多层链表,它有如下的性质:
- 多层的结构组成,每层是一个有序的链表
- 最底层的链表包含所有的元素
- 跳跃表的查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)
对象
Redis 的对象系统还实现了基于引用计数技术的内存回收机制: 当程序不再使用某个对象的时候, 这个对象所占用的内存就会被自动释放; 另外, Redis 还通过引用计数技术实现了对象共享机制, 这一机制可以在适当的条件下, 通过让多个数据库键共享同一个对象来节约内存。